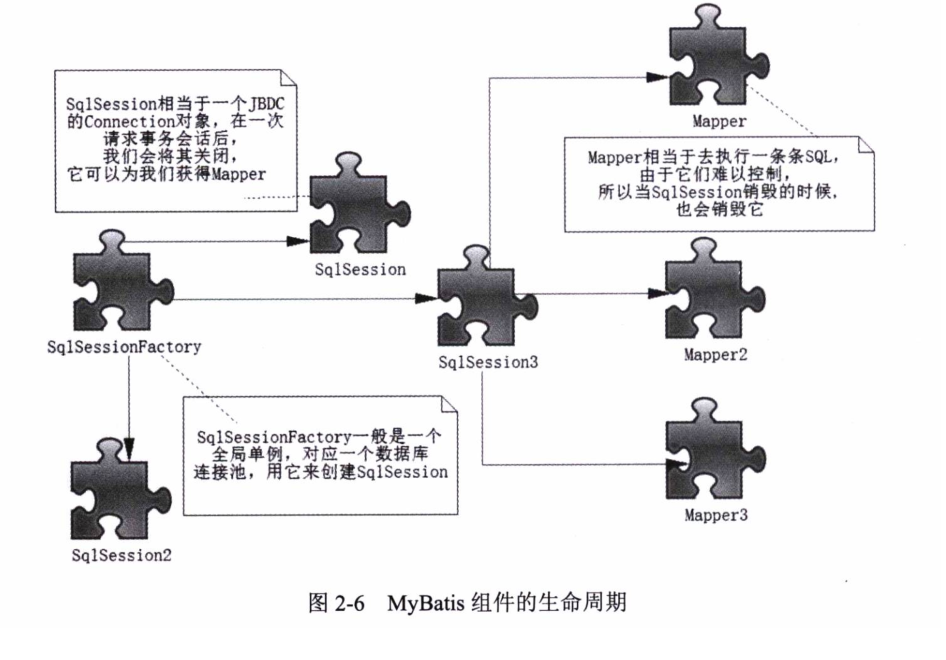
1. XML方式与注解方式对比
使用Mapper.xml的方式
优势:和接口分离,便于统一管理; 复杂的语句不会影响接口的可读性,可以带来更灵活的空间
劣势:存在较多的XML文件
使用注解的方式
优势:在接口层就能看到对应的SQL,不需要再去查找xml文件,可读性高,较为方便
劣势:如果存在较为复杂的联合查询,那么会因为SQL语句过长而影响阅读,导致可读性降低;另外,这种方式的SQL无法进行复用,也就是无法使用xml文件中的include方式。
2. 配置文件 mybatis-config.xml中配置的每一个信息都可以在org.apache.ibatis.session.Configuration类中找到对应的属性,其实说白了,在xml中配置这么多的属性,就是为了组装这个Configuration的
属性配置 mybatis的配置文件中的值可以在外部配置,可以通过配置properties文件的方式。在mybatis-config.xml中以如${ driver.class }的方式引入。
如果在项目中多处配置了属性的值,优先级如下:
方法参数传递的属性 –> properties resource中指定的URL文件 –> 最后是properties体中指定的属性
切记不要使用混合的方式,否则会使得代码看上去很混乱,首选的方式应该是properties文件的方式
如果系统有对密码、用户名等进行加解密的需求,建议使用配置properties文件,然后通过代码方式来创建SqlSessionFactory的方式。
从mybatis3.4.2开始,可以为占位符设定一个默认值,如:${username: mysql},这里如果username没有配置的话,那么将取mysql作为参数值。如果需要使用这一特性,必须要启用默认值特性:
1 2 3 4 <properties resource ="org/mybatis/example/config.properties" > <property name ="org.apache.ibatis.parsing.PropertyParser.enable-default-value" value ="true" /> </properties >
设置(settings) 是Mybatis最复杂的配置,也是Mybatis最重要的配置之一,它可以改变Mybatis运行时的行为。比如配置proxyFactory指定Mybatis创建具有延时加载能力的对象所使用到的代理工具等。
1 2 3 <settings > <setting name ="cacheEnabled" value ="true" > </setting > </settings >
别名(typealias) 可以使用一个简短的名称来代替类的全限定名,这个名称可以在Mybatis的上下文中使用。别名是不区分大小写的,别名是在解析配置文件中生成,并长期保存在Configuration对象中的,在需要的时候取出来即可,这样就可以不用在运行时再创建它的实例了。
Mybatis为我们定义好了常用的类型的别名,比如:数值、字符串、日期和集合等,这里展示部分TypeAliasRegistry中的配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 registerAlias("date[]" , Date[].class); registerAlias("decimal[]" , BigDecimal[].class); registerAlias("bigdecimal[]" , BigDecimal[].class); registerAlias("biginteger[]" , BigInteger[].class); registerAlias("object[]" , Object[].class); registerAlias("map" , Map.class); registerAlias("hashmap" , HashMap.class); registerAlias("list" , List.class); registerAlias("arraylist" , ArrayList.class); registerAlias("collection" , Collection.class); registerAlias("iterator" , Iterator.class); registerAlias("ResultSet" , ResultSet.class);
当然也可以自定别名,通过标签:
1 2 3 4 5 6 7 <typeAliases > <typeAlias alias ="testAlias" type ="com.summer.test.TestAlias" > </typeAlias > <package name ="com.summer.domain" /> </typeAliases >
包扫描的方式可以配合注解的方式使用,如果没有使用Alias注解的话,也是会被扫描的,只不过是将类的首字母小写作为别名
1 2 3 4 @Alias ("role" )public class Role ... }
typeHandler类型处理器 Mybatis在预处理语句中( PreparedStatement ),在设置每一个参数或者从结果中取出一个值时,都会用注册了的typeHandler进行处理。
也分为系统定义和自定义两种,但是一般来说,使用系统已经设置好的就已经可以完成大部分功能
系统定义部分展示:
1 2 3 4 5 6 register(String.class, JdbcType.NVARCHAR, new NStringTypeHandler()); register(String.class, JdbcType.NCHAR, new NStringTypeHandler()); register(String.class, JdbcType.NCLOB, new NClobTypeHandler()); register(JdbcType.CHAR, new StringTypeHandler()); register(JdbcType.VARCHAR, new StringTypeHandler()); register(JdbcType.CLOB, new ClobTypeHandler());
自定义typeHandler 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 package com.epoch.mybatis.study.typehandler;import org.apache.ibatis.type.JdbcType;import org.apache.ibatis.type.MappedJdbcTypes;import org.apache.ibatis.type.MappedTypes;import org.apache.ibatis.type.TypeHandler;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.sql.CallableStatement;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.sql.SQLException;@MappedTypes ({String.class})@MappedJdbcTypes (JdbcType.VARCHAR)public class MyStringTypeHandler implements TypeHandler <String > Logger logger = LoggerFactory.getLogger(MyStringTypeHandler.class); @Override public void setParameter (PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException logger.info("设置MyStringTypeHandler类型数值..." ); ps.setString(i, parameter); } @Override public String getResult (ResultSet rs, String columnName) throws SQLException logger.info("获取MyStringTypeHandler类型数值..." ); return rs.getString(columnName); } @Override public String getResult (ResultSet rs, int columnIndex) throws SQLException logger.info("使用MyStringTypeHandler获取下标字符串" ); return rs.getString(columnIndex); } @Override public String getResult (CallableStatement cs, int columnIndex) throws SQLException logger.info("使用MyStringTypeHandler CallableStatement获取下标字符串" ); return cs.getString(columnIndex); } }
枚举类型typeHandler Mybatis为我们提供了两种类型的typeHandler:EnumTypeHandler、EnumOrdinalTypeHandler
EnumTypeHandler:使用枚举字符串的名字作为参数传递
EnumOrdinalTypeHandler:使用整数下标作为参数传递,是Mybatis默认的枚举类型处理器
在更多的应用场景中,我们希望使用呢我们自己的typeHandler来处理枚举类型。比如我们在定义了Sex枚举类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package com.epoch.mybatis.study.enums;public enum Sex { MALE(1 , "男" ), FMALE(2 , "女" ); private Sex (Integer id, String name) this .id = id; this .name = name; } private Integer id; private String name; public Integer getId () return id; } public void setId (Integer id) this .id = id; } public String getName () return name; } public void setName (String name) this .name = name; } public static Sex getSex (int id) if (id == 1 ) { return MALE; } else if (id == 2 ) { return FMALE; } return null ; } }
之后,可以在Mybatis中添加如下配置:
1 2 3 <typeHandlers > <typeHandler handler ="org.apache.ibatis.type.EnumOrdinalTypeHandler" javaType ="com.xxx.xxx.Sex" /> </typeHandlers >
然后在resultMap中:
1 <result column ="sex" property ="sex" typeHandler ="org.apache.ibatis.type.EnumOrdinalTypeHandler" />
如果系统提供的两个枚举类型处理器都不能满足我们的要求,我们可以通过实现TypeHandler接口来自定义自己的枚举类型转换器
ObjectFactory 当Mybatis在构建一个结果返回的时候,都会使用到ObjectFactory(对象工厂)来创建一个pojo。Mybatis有自己的默认的对象工厂的实现类DefaultObjectFactory,如果我们想要定义我们自己的对象工厂,那么可以通过继承DefaultObjectFactory或者实现ObjectFactory接口来实现。然后进行如下配置:
1 2 3 <objectFactory type ="com.summer.mybatis.MyObjectFactory" > <property name ="name" value ="MyObjectFactory" /> </objectFactory >