Broker:相当于一个ActiveMq服务器实例
命令行启动:activemq start,使用默认的ActiveMq.xml启动
activemq start xbean:file:../conf/ActiveMq-bak.xml:使用指定的配置文件启动
构建java应用
嵌入式broker启动
1 | // 使用BrokerService启动 |
Broker:相当于一个ActiveMq服务器实例
命令行启动:activemq start,使用默认的ActiveMq.xml启动
activemq start xbean:file:../conf/ActiveMq-bak.xml:使用指定的配置文件启动
1 | // 使用BrokerService启动 |
公司部署的应用是一整套应用服务,在一个Tomcat中包含5个子模块,其中有两个是做数据级联操作,也就是保存各子系统推送的数据,并向它的上级推送。这两个模块对数据库的访问尤其是插入操作比较频繁。另外,这台服务器还部署了MySQL,Redis,Mq等应用
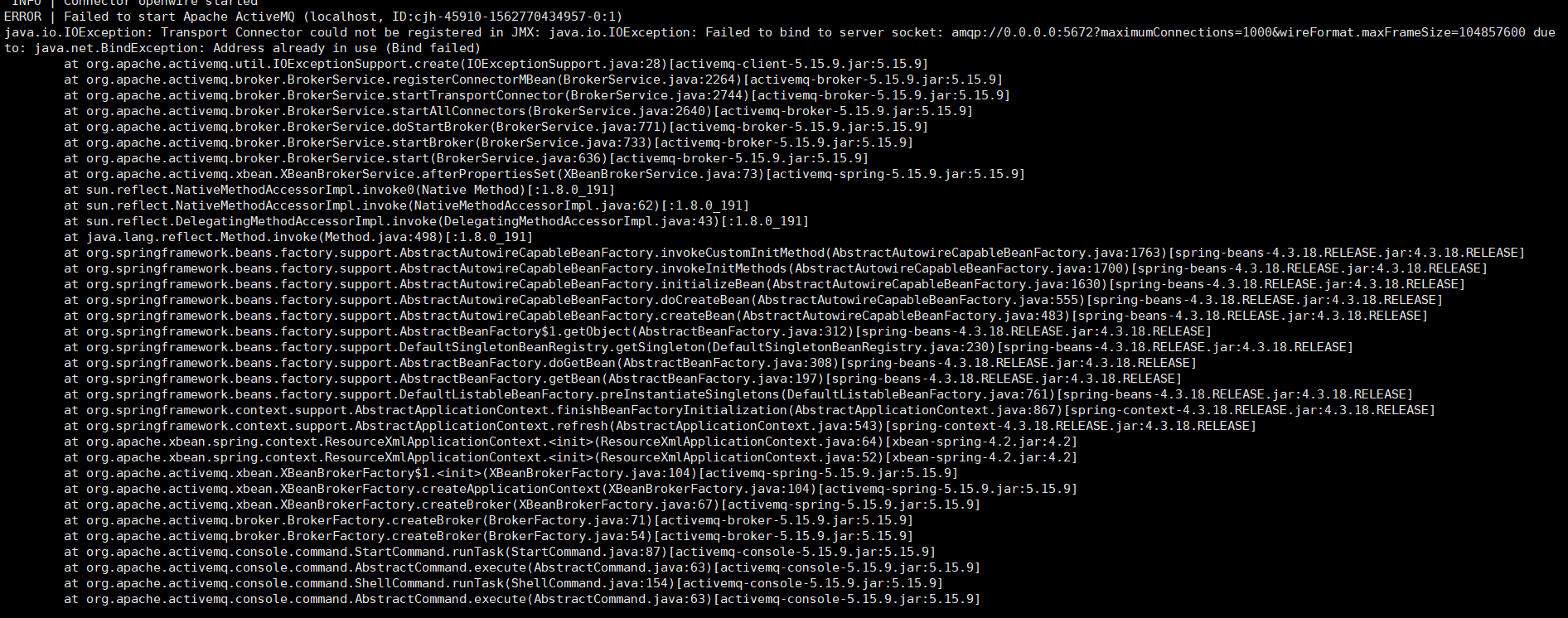
今天早上现场人员说web平台又崩溃了,访问不了,查看应用日志发现大量的MySql Too Many Connections异常,第一反应数据库连接被占满了,导致没有空闲的连接可以使用了。这个时候无论是使用mysql命令直连数据库还是通过Navicat连接数据库都连接不上,show full processlist命令根本使用不了,无法定位是哪个应用出的问题,所以只能先回收被占用的连接,让数据库恢复正常使用。
使用如下命令,查看当前连接状况
1 | netstat -an | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]' |
执行结果如下:
1 | TIME_WAIT 42906 |
发现大量的MySQL连接处于TIME_WAIT状态,只有少数处于连接状态,这显然是不正常的
可以通过调整内核参数来回收这些处于TIME_WAIT状态的
1 | vim /etc/sysctl.cnf |
net.ipv4.tcp_syncookies = 1表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout修改系統默认的TIMEOUT时间
使用命令 /sbin/sysctl -p 使刚修改的参数生效
再次使用命令查看,明显的发现TIME_WAIT的数量减少了,mysql可以重新连上了
现场恢复使用后,开始排查是什么原因导致的,打开每个模块的配置文件,看到每个模块配置的druid的最大连接数都为200,查看 mysql/conf/my.cnf文件,发现这里配置的 max_connections 为500,max_connect_errors=10000,那么推测,当平台设备上报的采集的人脸、车辆等抓拍记录较多的时候,可能会将整个 druid的连接数全部占用,由于每个模块的最大连接均为200,那么是有可能达到数据的最大连接数500的
随后修改了每个模块的连接数大小为50,并将先前修改的内核参数还原回去,重启应用,观察情况
应用到目前为止还处于正常运行状态,需要再进一步观察
出现以上问题的原因可能是因为项目中连接池配置不合理导致的,那么应该如何去配置呢
当配置的连接数过大时,可能因为线程间的上下文切换频繁而导致性能的下降,因为大部分的数据库都是将数据存储在磁盘上的,那么在进行数据访问时就必然的要进行磁盘IO操作,在这段时间内,线程是处于“阻塞”状态的,那么此时操作系统可以将这个空闲的CPU服务于其他线程,等IO操作完毕后再切回来。所以,当我们处理的业务是IO密集型的业务时,我们设置的连接数大小可以比核心数大些,这样可以提高吞吐量。
至于,需要设置成多大,还和网络IO,磁盘类型,带宽等有一定的关系,比如,在使用SSD硬盘时,由于读写快,IO阻塞的时间小,可以将连接数设置的更小一些,带宽高的又会比带宽小的阻塞小一些,也可以设置的更小一些。
可以参考的连接数计算公式:(核心数 * 2 ) + 有效磁盘数)
应该尽量去设置一个合适的小连接池和一个等待连接的线程队列,不宜设置过大,像我们最开始设置的200,显然是过大了。
队列的发送和接收相对于topic更简单一些,就只拿topic做简单示例
1 | /**************************创建发布者**********************************/ |
1 | /**************************创建订阅者**********************************/ |
以上是一个对于持久订阅的topic的示例,需要注意的是,订阅者要先执行一次之后才能收到消费者处于非激活状态下的消息,因为消费者必须要告知JMS Provider自己的ID之后,消息中间件才能保存在这个客户端离线的时候,所有发送到客户端订阅的topic上的消息,并在该客户端上线之后将这些消息发给它
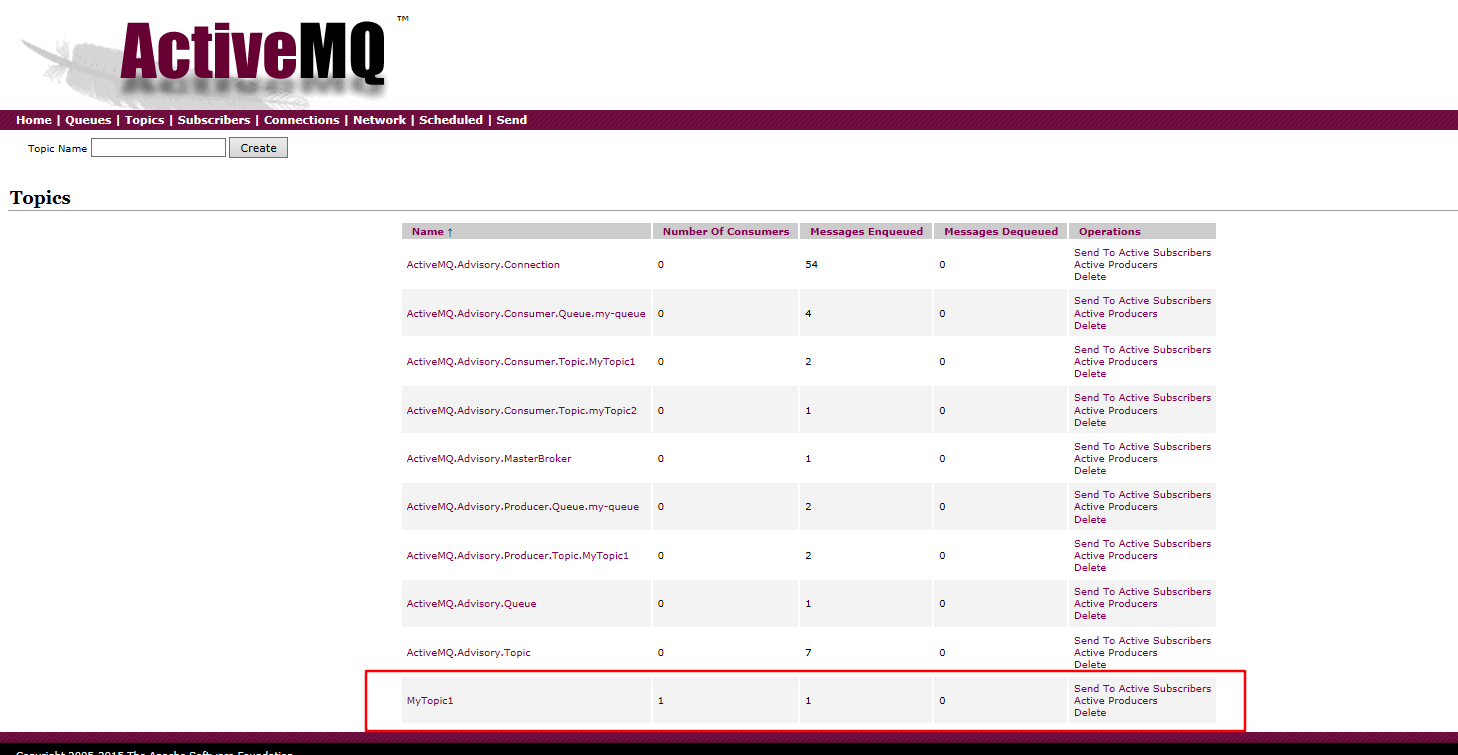
在向MyTopic1发送之后,在管理页面可以看到,topic中有一条消息
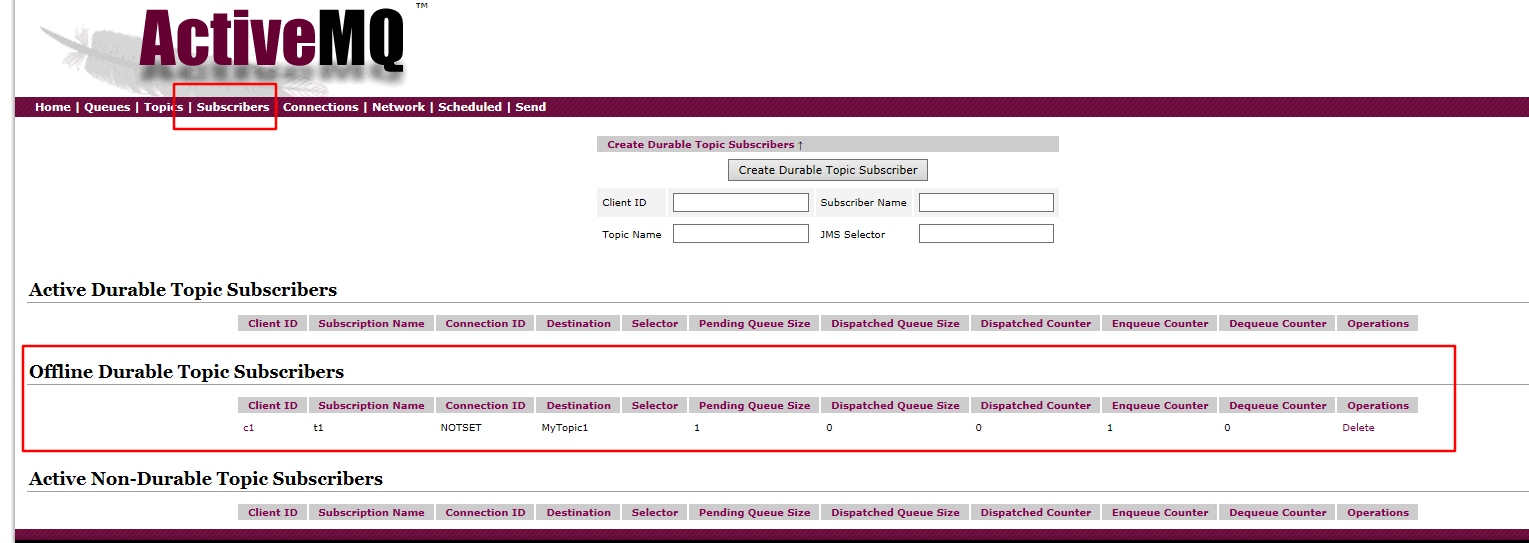
在Subscribiers中有一个订阅者,并且处于离线状态
当c1上线后就可以消费这条消息,但是出队的消息数量不会增加,因为其他的订阅者也可以订阅这个topic,保证同一个订阅者不会收到相同的消息就可以了
对于持久性消息而言,可靠性是优先考虑的因素,确保了消息服务在向消费者传送消息之前不会丢失,如果消息服务由于某种原因失败了,它会恢复消息并将此消息发送给消费者,这样增加了网络开销,但确保了可靠性
JMS Java Message Service,是一个Java消息服务,是J2EE中的一个技术
定义了Java访问消息中间件的接口,但是并没有给予实现。那些实现了JMS接口和JMS规范的称为JMS Provider 例如:ActiveMq
实现了JMS接口和规范的消息中间件
JMS的消息,由三部分组成:1. 消息头 2. 消息属性 3. 消息体(具体的消息数据)
消息生产者,创建和发送JMS消息的客户端应用
消息消费者,是接收和处理JMS消息的客户端应用
消费者有两种消费方式:
1. 同步消费:消费者通过调用receive方法,从队列中显示的提取消息,如果队列中没有消息到达,那么receive方法会阻塞,直到消息到达
2. 异步消费:消费者向消息中间件注册一个消息监听器,定义当有消息到达的时候应当采取的动作,这样,当有消息到达的时候,消息中间件通过回调的方式来处理
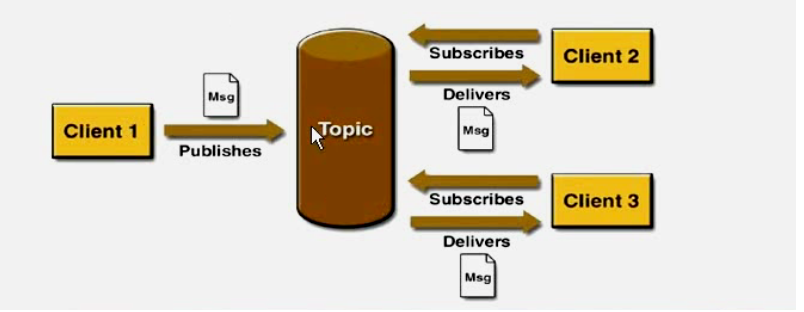
消息传递域,JMS规范中定义了两种消息传递域:点对点(Point To Point 简称P2P)、发布/订阅(Pub / Sub)
点对点的特点:
Pub / Sub 的特点:
在P2P中,消息的destination被称之为Queue ,而在Pub / Sub 中则被称之为Topic
JMS消息由三部分组成:消息头、属性和消息体
JMS Destination
消息发送的目的地,主要就是Queue或者Topic,在创建队列或者topic的时候会自动分配
JMS DeliveryMode
消息的传递模式,分为两种:持久模式和非持久模式,一条持久的消息只能被传送一次且仅有一次,当中间件发生故障的时候,这条消息并不会丢失,会在服务器恢复之后继续传递;一条非持久模式的消息最多会传递一次,当服务器发生故障的时候,这条消息会发生丢失
JMS Expiration
消息的过期时间,等于发送消息时设置的timeToLive值加上发送时刻的GMT时间值,如果 timeToLive的值为0,则表示该消息永不过期,直到等到消费者来消费。如果在设置了过期时间后,消息在指定的过期时间内没有发送到目的地,那么该条消息将会被清除,默认是0
JMSPriority
消息的优先级,有十个优先级,0–4表示普通消息,5–9表示加急消息,JMS不要求中间件一定要按照这十个优先级来发送消息,但是要保证加急消息一定要在普通消息到达之前到达,默认值是4
JMS MessageID
消息的标识ID,由JMS Provider产生,自动分配
JMS ReplyTo
提供本消息的回复消息的地址,由开发者设置,通过这个设置,可以在消费者消费消息之后给出一个应答,也就是在消息投递之后消费者消费的反馈
JMS Redelivered
消息的重新投递,如果一个客户端收到了消息设置了JMS Redelivered的属性,则表示之前可能已经接收过该消息,但是由于某种原因没有确认(acknowledge),如果该消息被重新投递,那么这个属性的值为true,反之则为false
由应用程序设置和添加的属性,比如:message.setStringProperty( “key”, “value”);
使用JMS定义的属性,使用JMSX作为消息的前缀,如:JMSXUserID:发送消息的用户标识,发送时提供商设置,JMSXAppID: 发送消息时的应用ID,发送时由提供商设置等等
一个消息只有被确认之后,才被认为是成功消费了,消息的成功消费通常需要包含三个阶段:客户端接收消息、处理消息和消息确认
在事务性会话中,当一个事务提交后,消息确认自动发生
1 | // 事务性会话,第一个参数为true |
在非事务性会话中,消息何时被确认取决于创建会话时的应答模式,有三种应答模式:
JMS支持两种消息提交模式,一种是持久的( PERSISTENT ),另外一种则是非持久性的(NON_PERSISTENT),持久性的消息不会因为JMS Provider的故障而丢失。这意味着持久性消息传送至目标时,消息服务会将其放入持久性数据存储,这会增加消息传送的开销,显然效率时候没有非持久性的高的
这个在之前有提过,共有10个级别,默认的级别是4,加急消息一定会先与普通消息到达,需要注意的是,JMS Provider不一定会按照消息的优先级提交消息(那如何保证加急消息一定先到达?)
可以设置消息的过期时间,默认是永不过期
1 | // 生产者创建临时queue |
临时目的地的存在时间只保持在创建它们的连接所保持的时间,只有创建了该临时目的地的连接上的消费者才能从这个队列中获取消息
持久订阅必须使用PERSISTENT提交消息,创建持久订阅的第一个参数必须是一个topic,JMS Provider会存储发布到持久订阅上的消息。如果最初创建持久订阅的客户或其他客户,使用相同的连接工厂和连接的客户ID,相同的topic,相同的订阅名,那么再次调用会话上的创建持久订阅的方法时,该持久订阅就会被激活,JMS Provider会向客户端发送客户端处于非激活状态时的消息。
持久订阅在某一时刻只能有一个订阅者,在被创建之后会一直保留,在会话调用unsubscribe( )方法时失效
JMS Session提供了commit( )和rollback( )方法来提交和回滚事务,事务的提交意味着生产的所有消息都将被提交,消费的所有消息都将被确认;回滚则生产的所有消息被销毁,消费的所有消息被恢复并重新提交,除非已经失效的消息,生产者和消费者的事务不能包含在同一个事务中
定义了客户端如何向队列发送消息,从队列接收消息,以及浏览队列中的消息,PTP模型是基于队列的,可以包含各中消息
如果在Session关闭时,有些消息已经被接收但是还没有被确认,那么当消费者下次再连接到队列时,这些消息不会被再次接收
如果在receive方法中设定了消息选择条件,那么不符合条件的消息将会留在队列中,不会被接收到
队列可以长久的保存消息直到消费者消费(没有设置过期条件的情况下),因此消费者不需要因为担心丢失消息而时刻和队列保持连接状态,这也提现出了异步传输的优势
定义了如何向内容节点发布和订阅消息,这些节点比称作topic,发布者发布消息到主题,订阅者从主题中订阅消息
在廉价的商用机器上单机可以支持每秒100万条消息的读写
所有消息均被持久化到磁盘上,无消息丢失,支持消息重放
Producer、Broker、Consumer均支持水平扩展
一般基于pull或者polling接收消息
发送队列中的消息被一个且只有一个接收者所接收,即使有多个消费者在监听同一个队列
既可以支持异步“ 即发即弃 ”的消息发送方式,也可以支持同步请求/应答的消息发送方式(即等到消费者成功返回之后再发送下一条消息)
发布到一个主题的消息,可以被多个订阅者接收
发布/订阅即可基于Push消费数据,也可以基于Pull或者Pollinig的方式消费数据
解耦能力比P2P模式更强
kafka是同时支持单播和多播的,kafka可以有不同的consumer-group,kafka支持不同消费者组之间的多播,每个consumer-group都会有consumer接收这条消息,也支持在group中的单播,在group中只会有一个consumer消费这条消息。
各个系统之间通过消息系统这个统一的接口交换数据,不用关心有哪些系统需要处理以及如何处理这条消息。
部分消息系统具有消息持久化的能力(如KafKa),可以规避消息处理前丢失的风险
消息系统是统一的数据接口,各系统可以独立扩展,不需要感知彼此间的变化
消息系统可以顶住峰值流量,系统可以根据自身的处理能力从消息系统中获取定量的请求进行处理,这样就可以在流量高峰期不会导致系统崩溃,也不会因为为了要应对流量高峰期而升级所带来的资源的浪费
系统中部分组件失效并不会影响整个系统,当它恢复后仍可以从消息系统中获取消息进行处理
在不需要立即对请求做出处理时,可以将请求放入到消息系统中,在适当的时候从消息系统中取出再进行处理
基于Erlang编写的,支持多协议:AMQP(语言无关), XMPP, SMTP, STOMP,支持负载均衡,数据持久化,同时支持P2P和发布/订阅模式,但是比较的重量级,适合在较为重量型的企业应用中
支持MQ功能,可以做轻量级队列服务使用,就入队而言,Redis对于短消息(小于10KB)的性能要比RabbitMq好,但是长消息的性能比RabbitMq差
JMS实现,P2P点对点模式,支持持久化,支持XA事务
高性能跨语言的分布式发布/订阅消息系统,支持数据持久化,全分布式,同时支持在线和离线的处理
纯Java实现,发布/订阅消息系统,支持本地事务和分布式XA事务
1 | public class SyncSingleton01 { |
这种方式虽然可以实现线程安全的单例模式,但是如果一个系统中这样的类存在较多的话,会拖慢系统启动的速度,所以,一般会使用延迟加载,在第一次使用的时候才初始化。
1 | public class SyncSingleton02 { |
这种方法锁的粒度比较大,而且在后面的每次获取这个对象的时候,都要进行上锁,效率自然也会是比较低的。
1 | public class SyncSingleton03 { |
这种方法采用了双重锁机制对第二种做了修改,减小了锁的粒度,在第一次调用之后,在获取对象的时候不需要再进行上锁。
1 | public class SyncSingleton04 { |
这种方式采用了无锁内部类的形式,也实现了懒加载,是较为优秀的实现方式。
使用了ThreadLocal之后,当前线程修改的值不会影响其他线程中该变量的值,也就是说这部分数据只会存在线程的独占区中。
1 | public class ThreadLocal01 { |
这里虽然线程c1修改了threadlocal的值,但是c2线程获取到的还是null。
题:创建一个固定容量的同步容器,拥有put和get以及getCount方法,支持2个生产者线程和10个消费者线程阻塞调用
1 | public class Question01<T> { |
这里有两个需要注意的地方,一个是判断的时候是使用的while循环判断,另一个唤醒线程使用的是notifyAll而不是notify。
原因:1. 这里之所以不能使用 if 判断的原因是,如果有多个生产者线程同时进入等待状态,此时消费者线程消费了数据,使用notifyAll唤醒所有的生产者线程,从等待的地方开始继续往下执行。假设此时 list 的size已经等于MAX - 1了,但是仍然有两个或者多个生产者线程处于等待状态,那么当其中的任何一个获得锁执行完之后,此时的list的长度已经达到最大值,那么当其他的线程获得锁,继续往下执行的时候,如果此时的判断是if (list.size() == MAX) 那么线程不会再次判断,而是直接执行list.add(t); 往list中添加数据,那么此时肯定会超过最大值了。而如果使用的是while的话,那么从wait的地方继续执行后面的代码的时候,还会再次进行判断,这样就不会超出最大容量了。所以,当使用wait的使用,99.9%的情况都是与while一同使用的。
原因:2. 如果使用的是notify的话,假如现在是生产者调用了notify,那么它不能保证它唤醒的一定是消费者线程,也有可能是生产者线程,如果唤醒的是生产者线程,那么又会进入到wait状态。
1 | public class Question02<T> { |
使用ReentrantLock的方式,可以精确指定哪些线程被唤醒,这样的效率明显是比synchronized效率要高的。